
例えばこれからSQLを学びたい、またGoogle BigQueryを試してみたいという場合、クラウドサービスの登録が初めてだと課金はどうなるのか、どのように使ったらいいのか不安なことがあるかと思います。
Google BigQueryは従量課金制です。使い方を間違えると高額な請求が来てしまうこともあるかと思いますので慎重に使いたいかと思います。
まずは勉強のために無料で使えるサンドボックス環境を用意して、どのようなものか学んでみるのが良いかと思います。
サンドボックス環境とはGoogle BigQueryを無料で試せる環境です。
サンドボックス環境はクレジットカードの登録なしで使えます。
主に検証用に準備されているため、実運用には向いていませんが勉強や事前検証などに使えるかと思います。
このコラムではサンドボックス環境の作り方についてご紹介します。
そもそもGoogle BigQueryとは
Google BigQueryとはビッグデータを高速で処理するためのサービスです。
DWH(データウェアハウス)のひとつです。
例えばですがGAのデータをBigQueryに送り、それをBigQueryからSQLで抽出したりできますので、必要なデータを抽出して分析するのに便利だったりします。
また、TableauやPower BIなどのBIツールからBigQueryに接続してデータを取得することもできます。
サンドボックス環境の制限事項について
無料で使える上限が設けられており、毎月 10 GB のアクティブ ストレージと 1 TB のクエリデータ処理が使えます。
よっぽど大きなデータ処理をしなければ1TBは超えないので検証する分には十分かと思います。
また、データセットをBigQueryに保存できるのですが、サンドボックスの場合有効期限は60日に設定されています。
そのため有効期限が切れた場合、再度データセットの登録が必要になります。
制約事項について詳しくは公式サイトを参照するようにしてください。

サンドボックス環境の作り方
Googleのアカウントを持っていない人は作成します。→Googleアカウントの作成方法
こちらのページにアクセスします。https://cloud.google.com/bigquery/docs/sandbox
「BigQueryに移動」をクリックします。
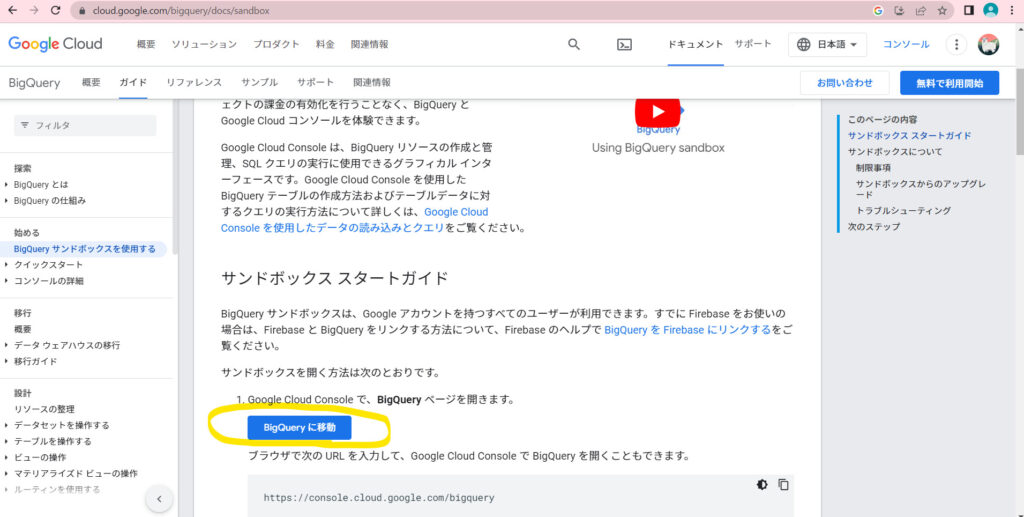
利用規約に同意するにチェックを入れ、「同意して実行」をクリックします。
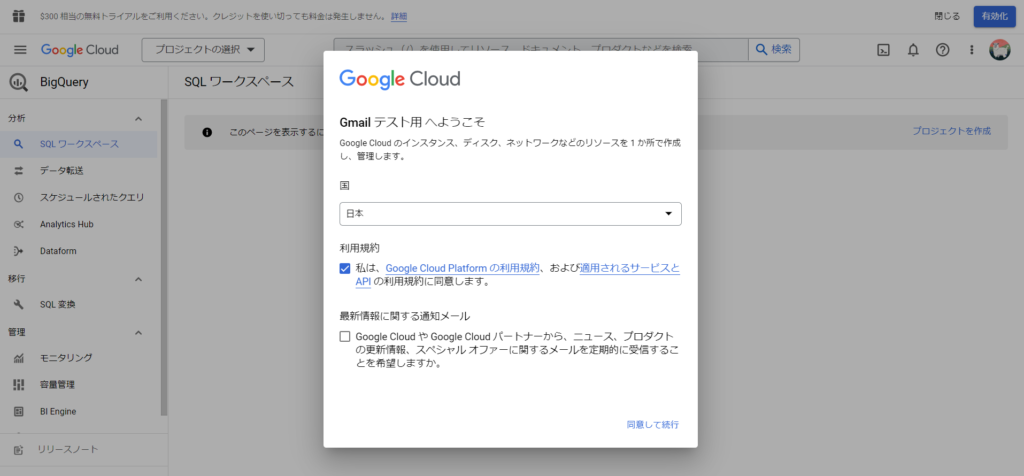
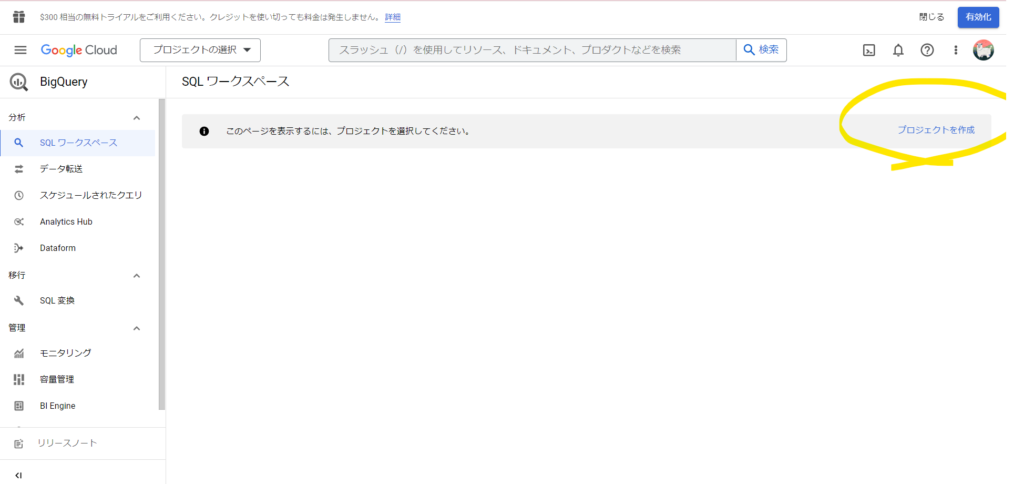
「プロジェクトを作成」をクリックします。
今回のBigQueryなどのGoogle Cloudの機能を使う場合は、基本的にプロジェクトを作成してその中で作業をすることになります。
サンドボックス環境も同様です。
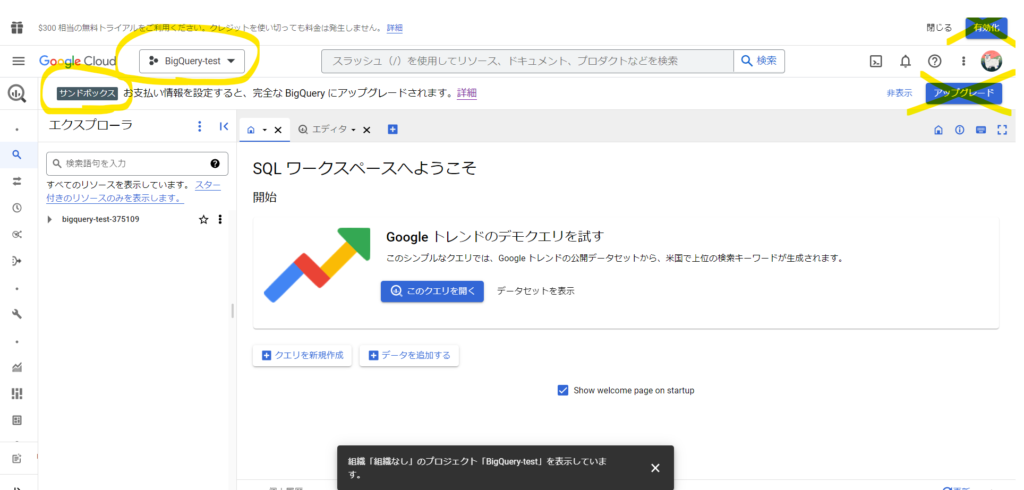
※【注意】ちなみに、画像右上の「有効化」はGoogle Cloudを実運用したい場合にクリックするところですので、今回のサンドボックス環境作成時にはクリックしないようにしてください。
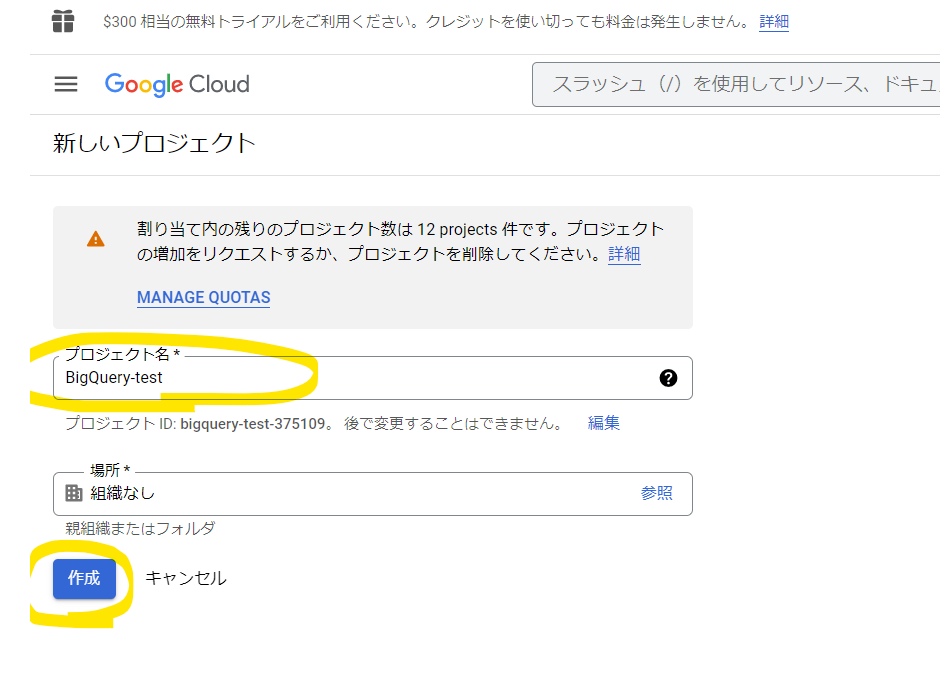
プロジェクト名は任意ですので、好きな名前を入力してください。今回は「BigQuery-test」とします。「作成」ボタンをクリックします。
このようなポップアップが出た場合、内容を確認して「完了」をクリックします。
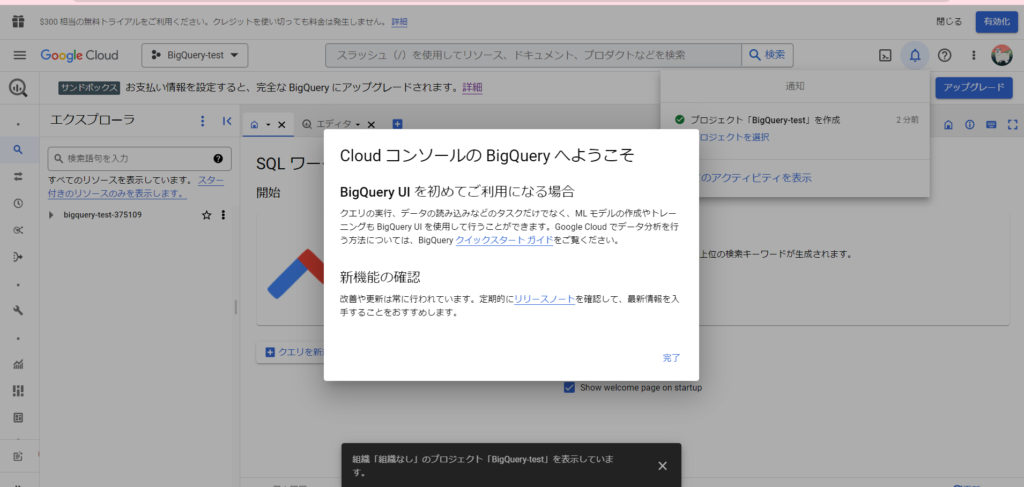
プロジェクトが作成されました。(下図)
左上にプロジェクト名が表示されているドロップダウンリストがあります。こちらで他のプロジェクトに変更することができます。
サンドボックス環境でも複数のプロジェクトを作成することができますので、用途に応じて使い分けできます。
この環境は無料のサンドボックス環境ですので、キャプチャの上の方を見ていただくと「サンドボックス」と表示されています。
※【注意】「有効化」や「アップグレード」はサンドボックス環境ではなく本当に契約するとき用ですので、今回はクリックしないようにしてください。
サンプルデータを登録する
それでは、データセットを作成します。
構造としては、データセットの下にデータテーブルが入ります。
一つのデータセットには複数のデータテーブルを入れることができます。
エクスプローラーの中に「プロジェクト名+数字」のリソース名が表示されていますので、その右のケバブメニューをクリックして
「データセットを作成」をクリックします。
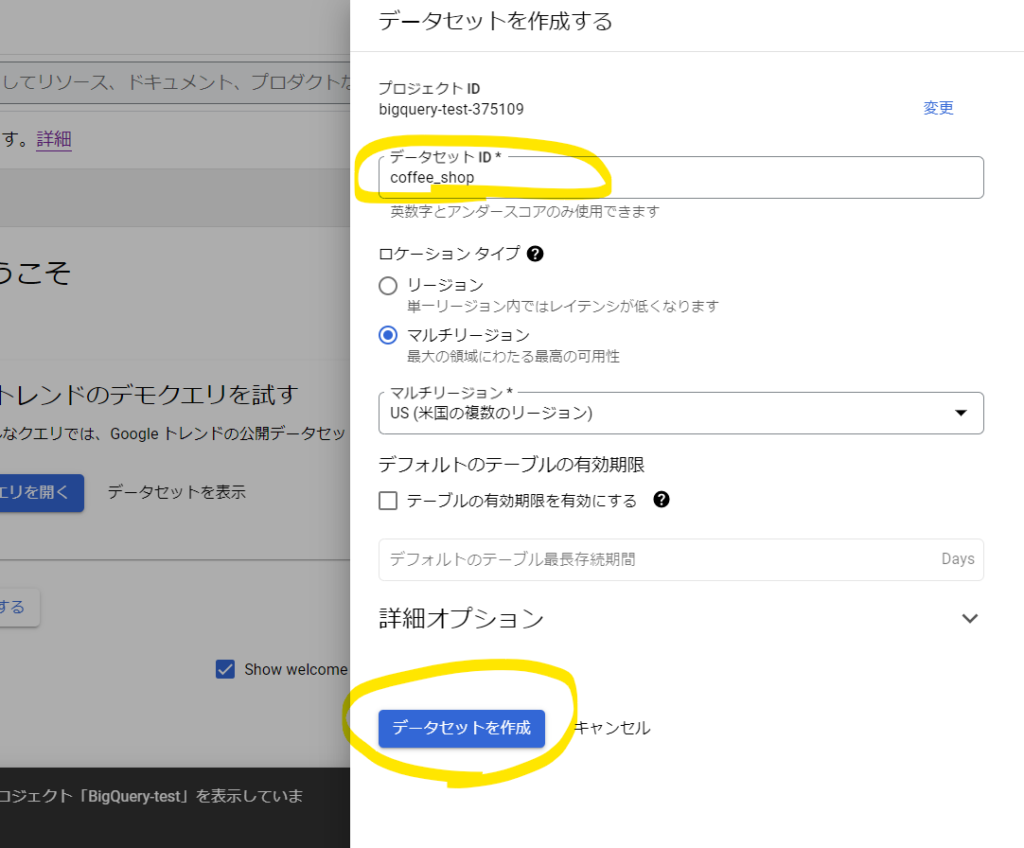
データセットIDは任意の名前を入力します(下図)。今回は「coffee_shop」としておきます。
ロケーションタイプはデフォルトのまま、「デフォルトのテーブルの有効期限」もそのままで問題ありません。
「デフォルトのテーブルの有効期限」はサンドボックス環境の場合60日が上限ですので、それ以上の期間の設定はできません。
60日よりも短くしたい場合、入力するとその期限が来たらデータが削除されます。
「データセットを作成」をクリックします。
エクスプローラーの中の「プロジェクト名+数字」のリソース名の左側の▶のボタンをクリックすると、下位に作成したデータセットが表示されるようになります。
まだこのデータセットの中にはデータが登録されていません。
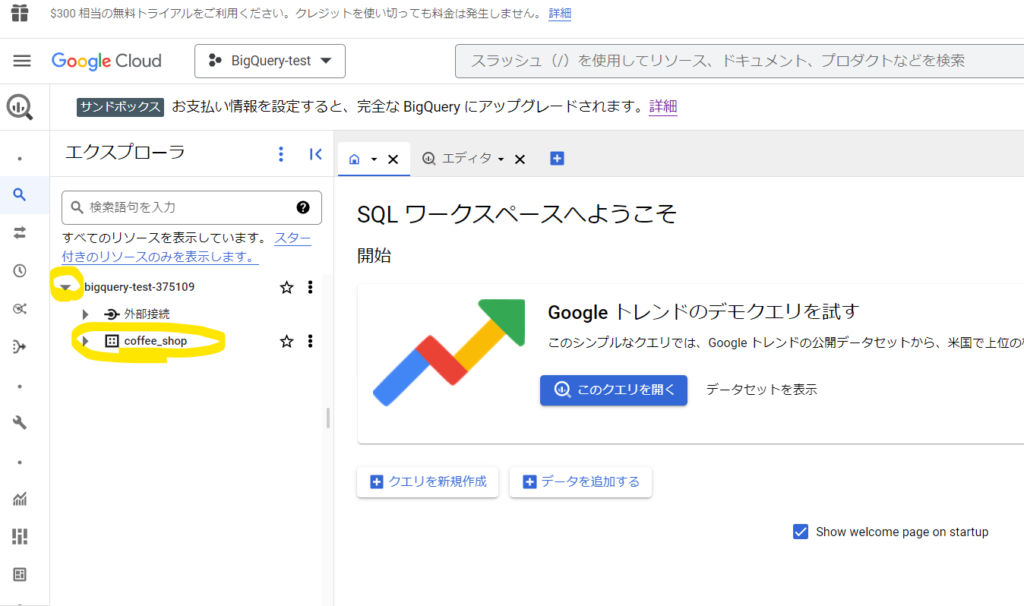
データセットの右のケバブメニューをクリックして「テーブルを作成」をクリックします。
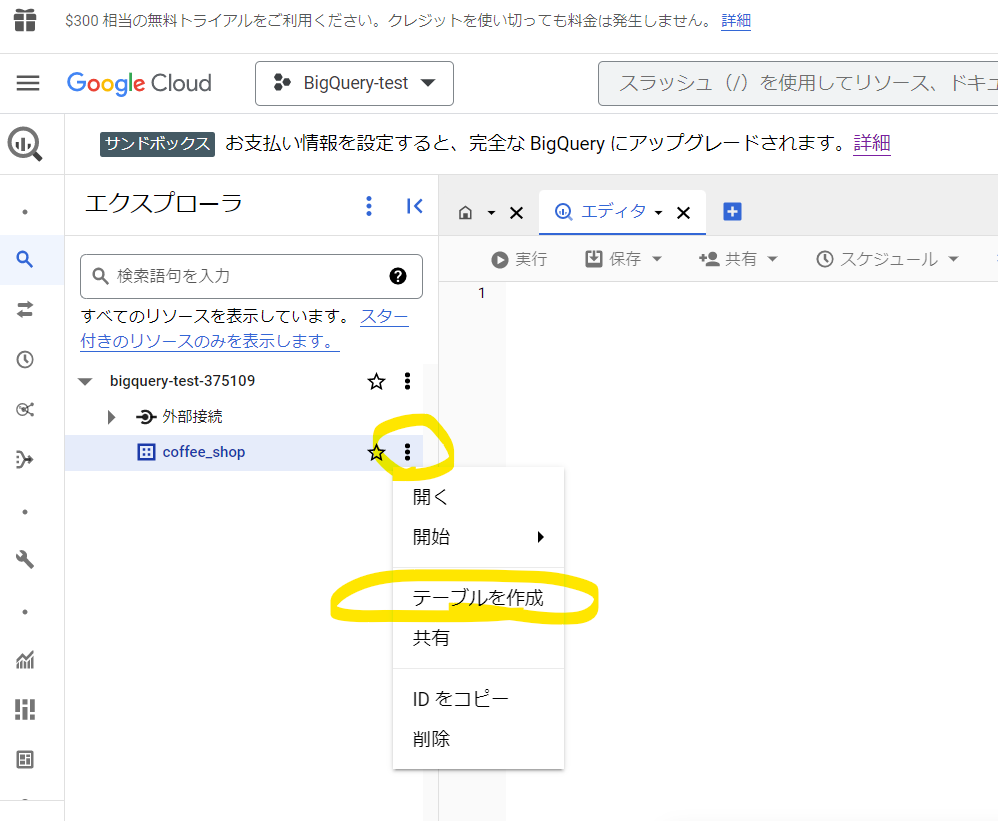
今回、サンプルデータを登録します。
サンプルデータのダウンロードはこちら↓ ※ボタンをクリックするとダウンロードされます。
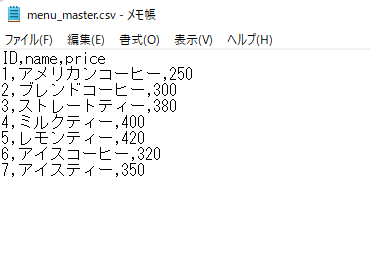
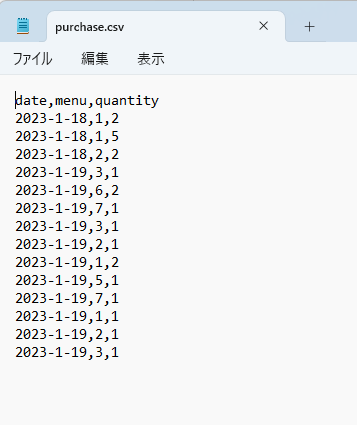
サンプルデータの内容はこのようなものです。
「テーブルを作成」画面で設定をします(下図)。
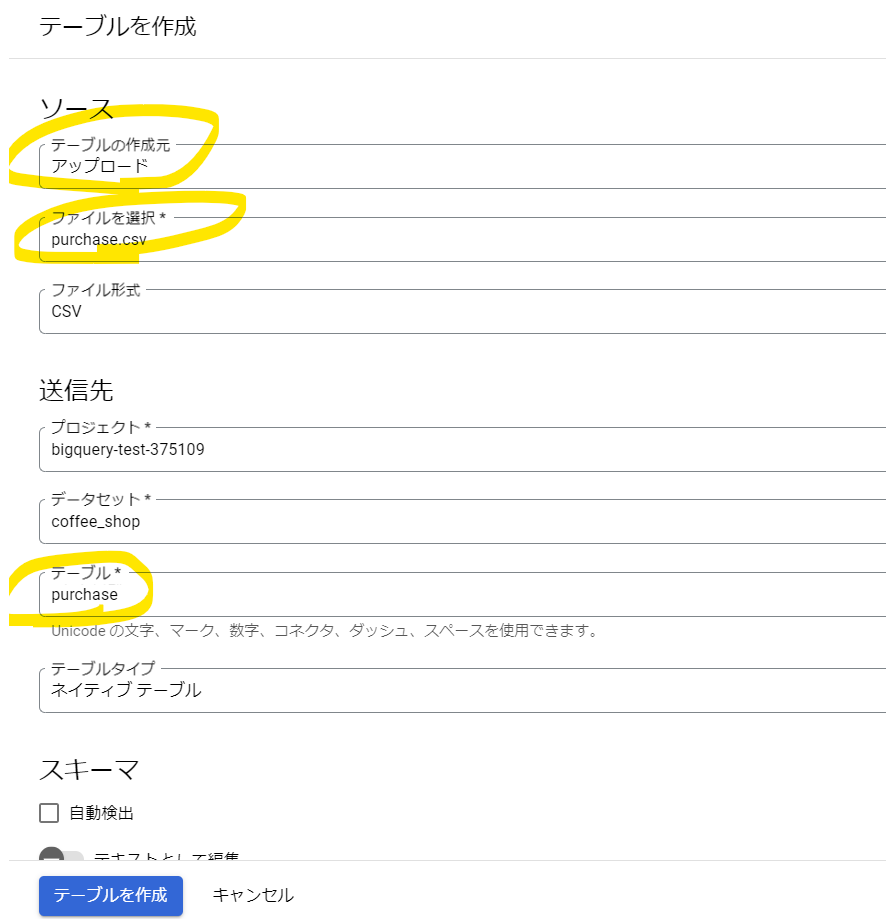
今回はファイルアップロードでデータを作成するので「ソース」の「テーブルの作成元」で「アップロード」を選択します。
「ファイルを選択」で「参照」からサンプルデータのmenu_master.csvを選びます。
テーブル名はここでは「menu_master」とします。

スキーマを登録します。「自動検出」を使うとデータを見てBigQuery側で判断をしてデータ型などを自動で検出、設定してくれます。
今回は明示的に指定して登録をしたいと思います。
「フィールドを追加」をクリックします。
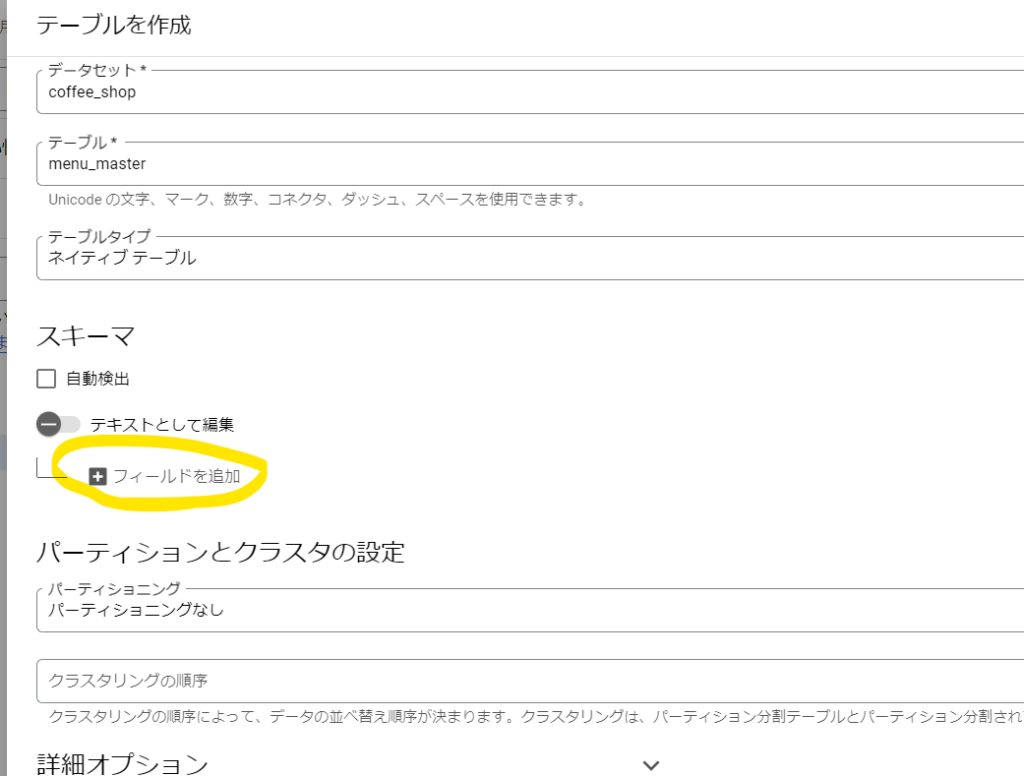
下図のようにフィールド名とタイプ(データ型)、モードを設定します。
モードの設定について、IDはNULL値を許可せず、name、priceはNULL値を許可しておきます。

「詳細オプション」を開きます。
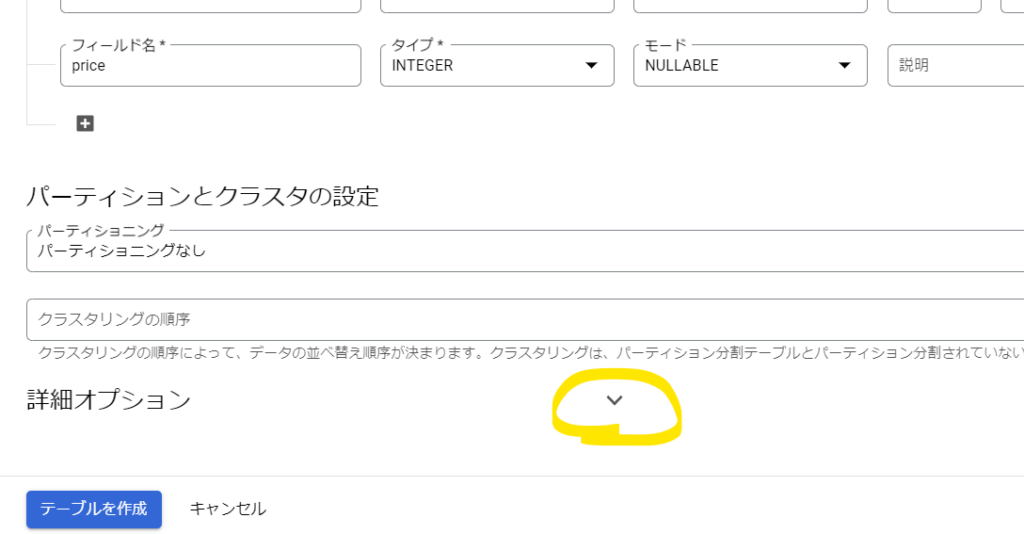
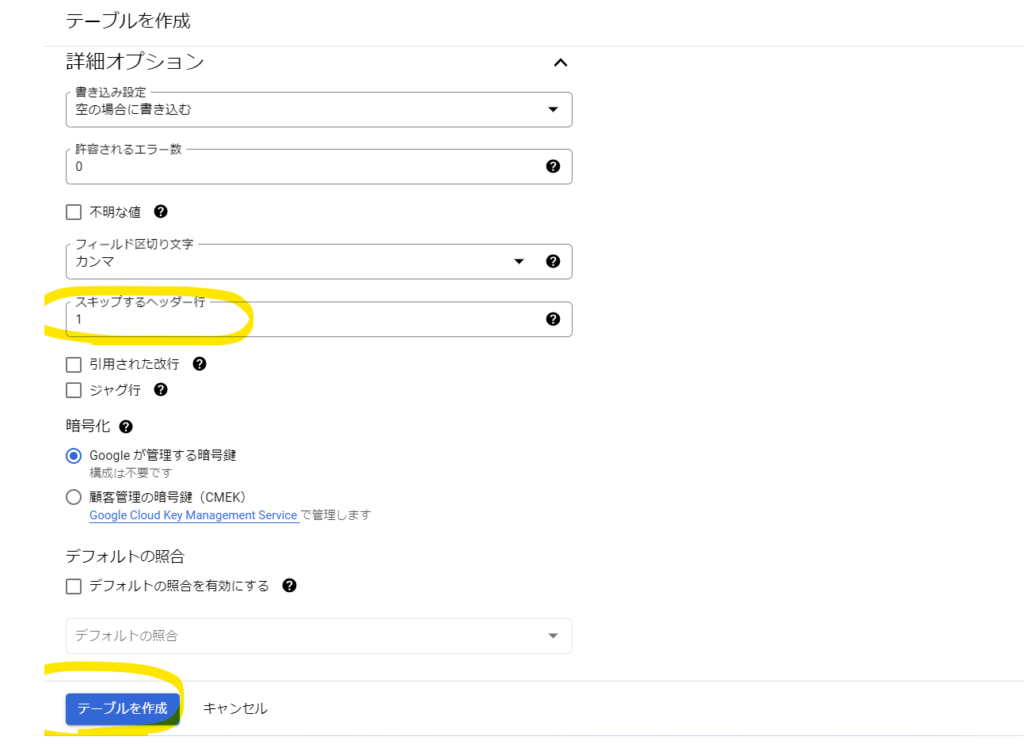
「スキップするヘッダー行」に1と入力します。CSVの1行目をヘッダー行として扱うという意味です。
「テーブルを作成」をクリックします。
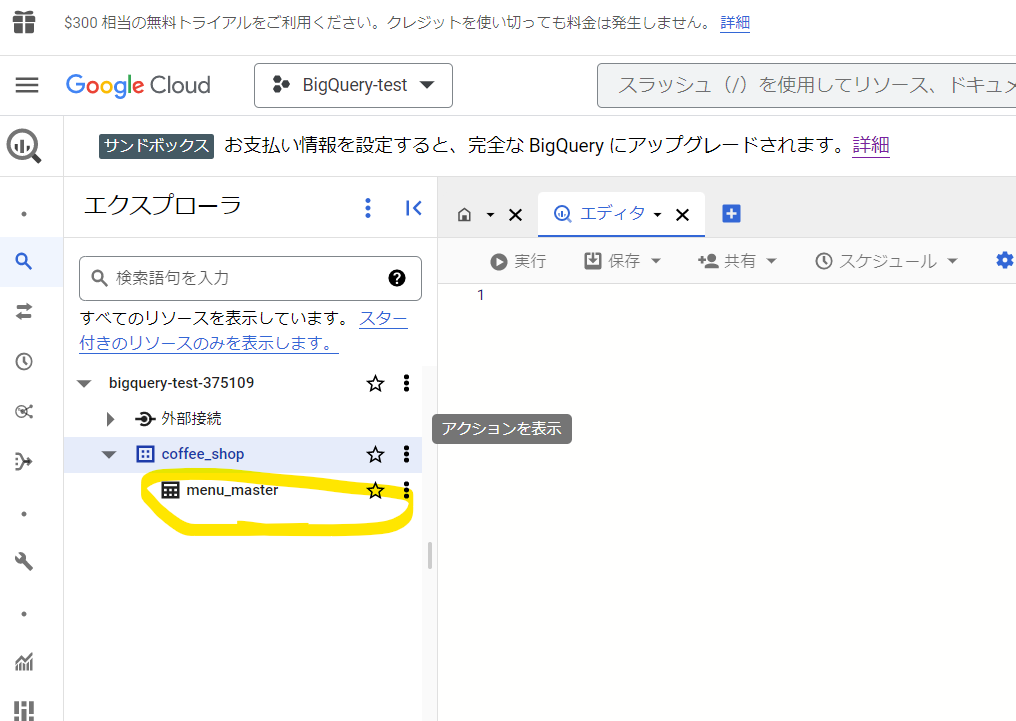
データセット「coffee_shop」の下に「menu_master」テーブルが表示されました。
「menu_master」テーブルの名前をクリックするとスキーマの内容を確認できます。
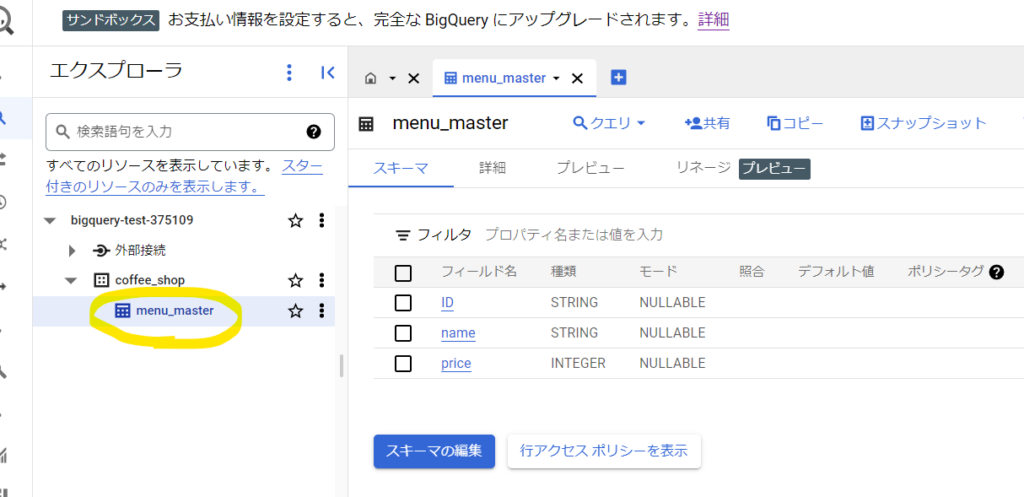
また、「プレビュー」をクリックするとデータの中身が確認できます。プレビューは 1 TB のクエリデータ処理の対象にはなりませんのでクエリを実行する前にデータの中身を確認したい場合はプレビューを使います。
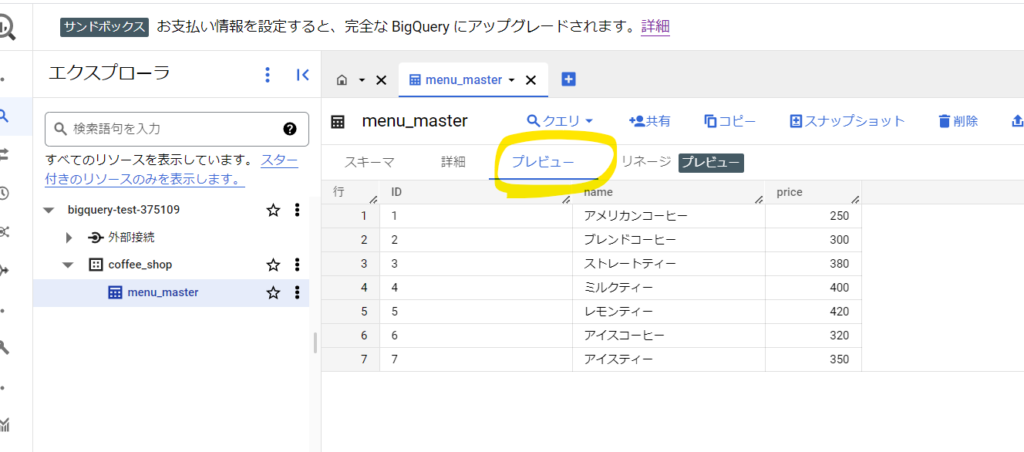
同様にpurchase.csvを使いテーブルを登録します。

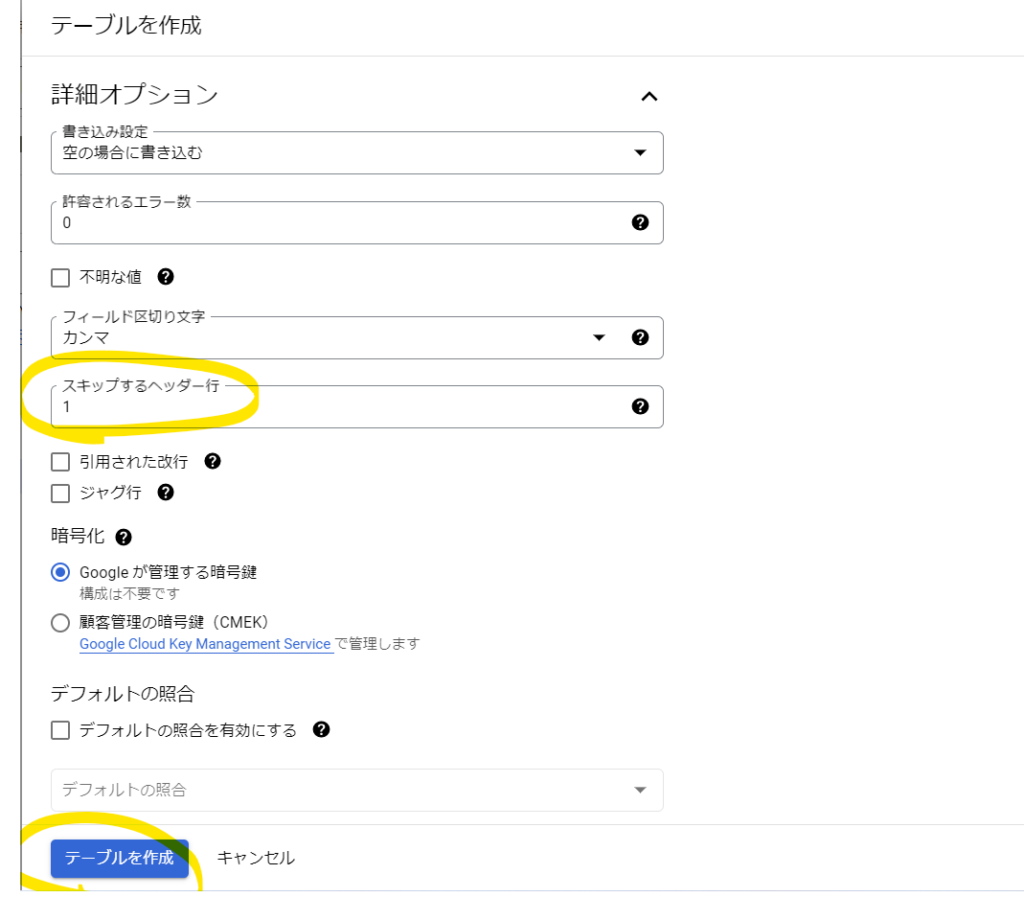
「purchase」テーブルが作成されました。
それではクエリを実行してみます。
+ボタンをクリックして「クエリを新規作成」します。
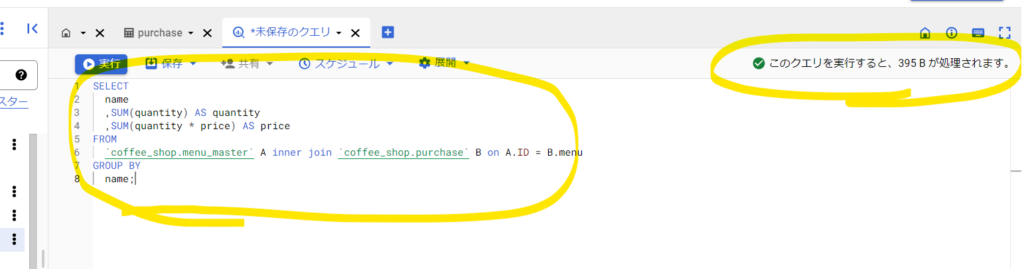
エディタが開くので、例えばこちらのSQLをエディタに記載します。
SELECT
name
,SUM(quantity) AS quantity
,SUM(quantity * price) AS price
FROM
`coffee_shop.menu_master` A inner join `coffee_shop.purchase` B on A.ID = B.menu
GROUP BY
name;すると、「このクエリを実行すると、395 B が処理されます。」と表示されます。このデータ量は 1 TB のクエリデータ処理の対象に入りますので、1か月の上限を超えて使うことはできません。クエリを実行する前にはデータ量を確認する癖をつけておくと良いです。
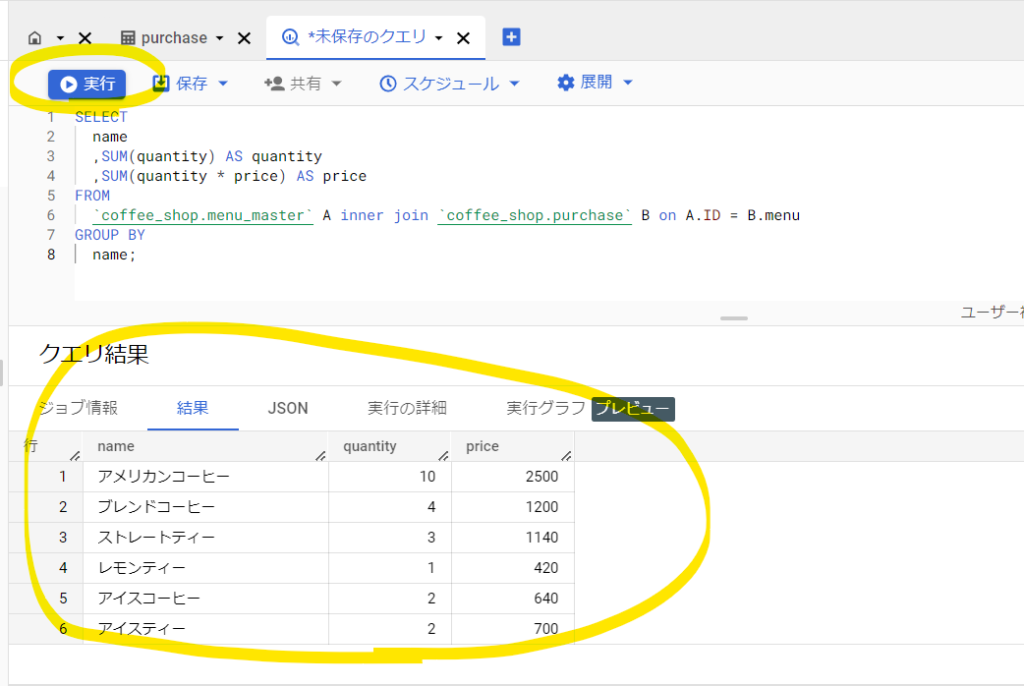
「実行」ボタンをクリックするとクエリが実行されクエリ結果が表示されます。
次からサンドボックス環境に接続する場合
サンドボックス環境を作成したあとにブックマークしておいても良いですが、サンドボックス環境へのアクセス方法について最後に説明します。
ブラウザでBigQueryなどと検索して、下記のページを開きます。
右上の「コンソール」リンクをクリックします。
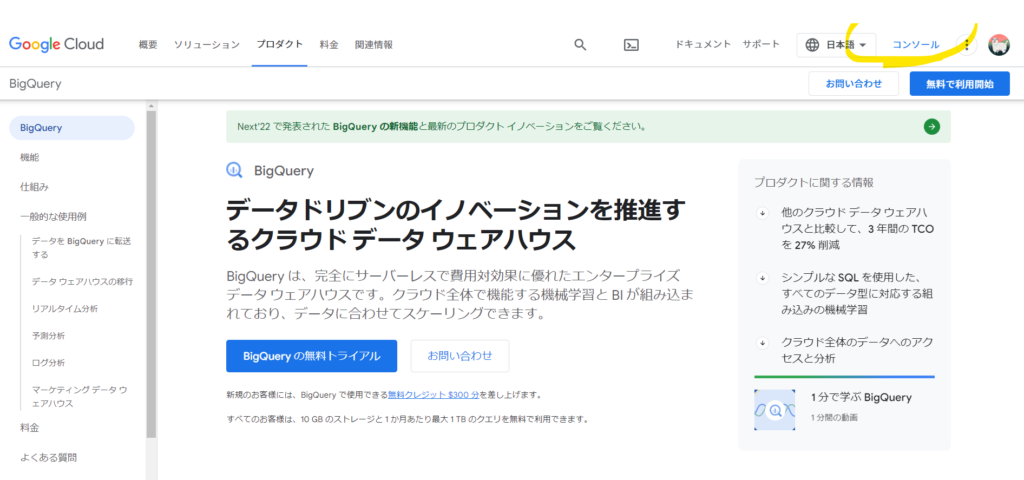
左上のプロジェクト名がサンドボックス環境で設定したプロジェクト名であることを確認し、「BiqQueryでクエリを実行」ボタンをクリックします。
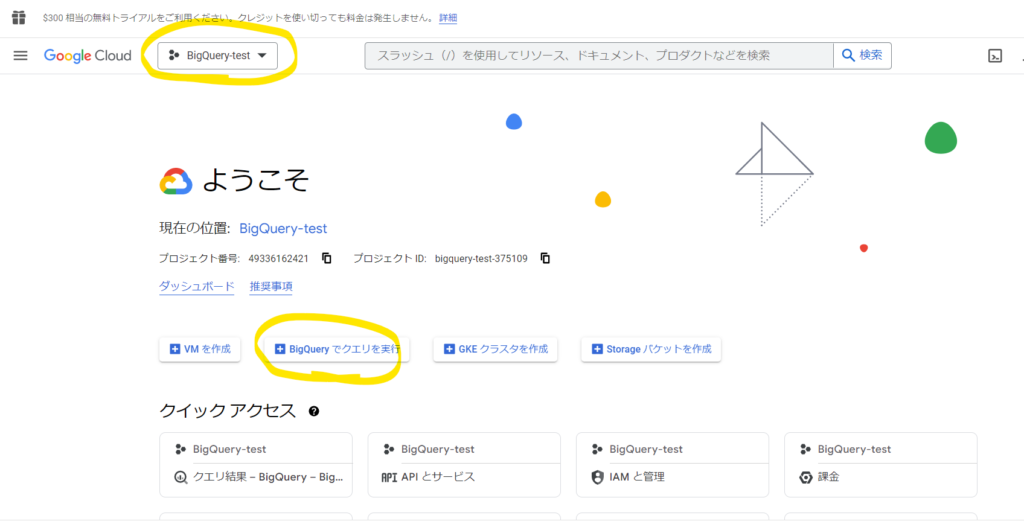
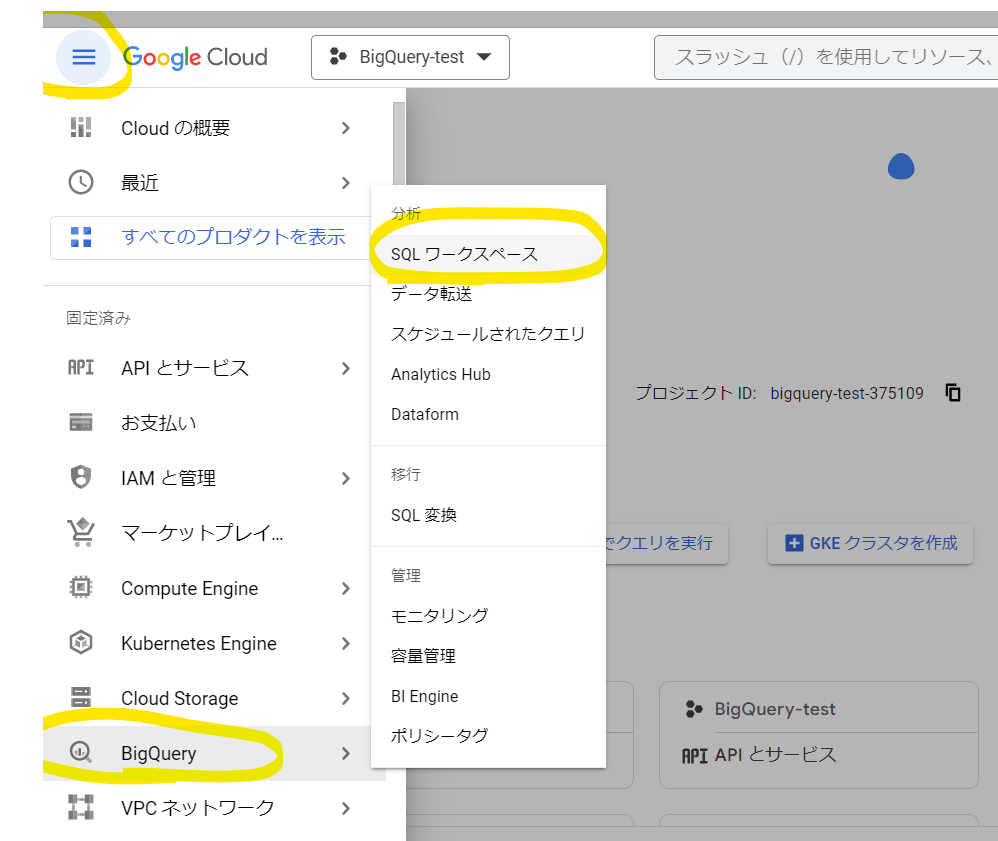
もしくは別の方法として、左上のハンバーガーメニューから「BigQuery」を選択し「SQLワークスペース」をクリックして開きます。
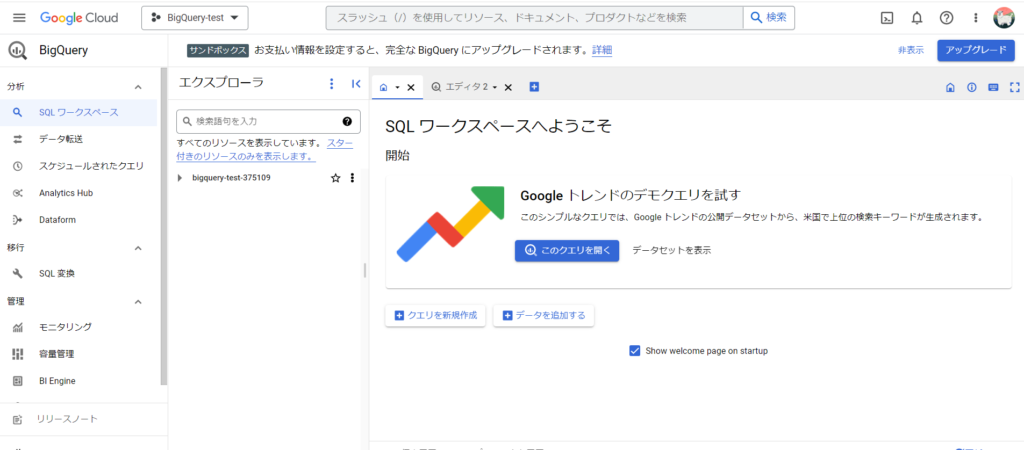
SQLワークスペースが開きました。
最後に
以上でGoogle BigQueryのサンドボックス環境の作成方法は終わりです。
このコラムを書いた時点の情報ですので、最新の情報は公式サイトを参照するようにしてください。
